
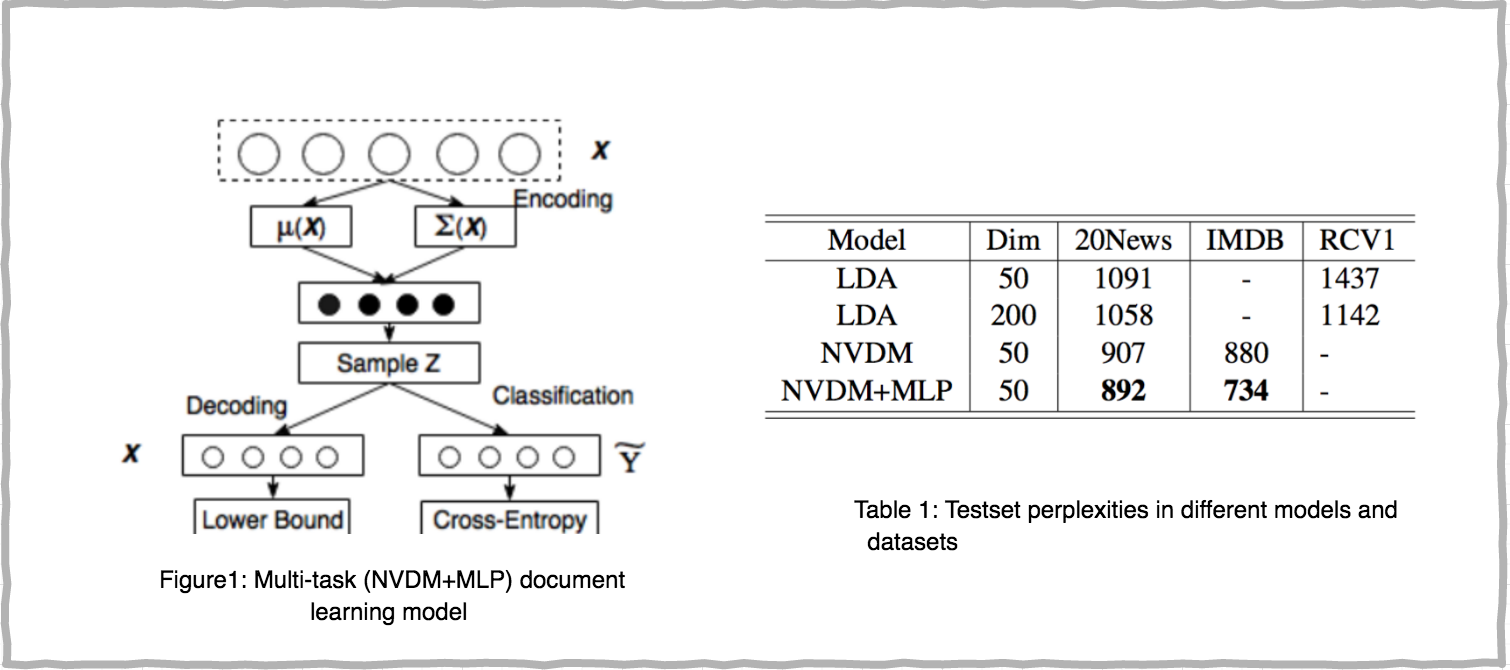
Documents Classification with VAE
Recent study in auto-encoder framework has led to advances in natural language processing. One challenging but critical task in modeling text data is to learn the document level representation. We shed some light on the possiblity of combining
traditional lingural features with a probabilistic auto-encoder model (VAE), on a level of document representation, to improve the quality and robustness of a document classification system. For more details about the project, check our poster here!
Sequence and Document representation methods summary
One approach to build unsupervised representation learning framework is through generative modeling. The nature of text data, including discreteness or an recurrsive structure, makes it more difficult to be modeled, particular the models delievered from other communities such as vision. We hereby focus on collecting
and summarizing recent developments on such challenging task. The methods being studied include variational autoencoder, NVDM for document modelling, generating sentence with VAE, paragraph vector model, skip-thought model, sequence autoencoder, and multi-task sequence to sequence learning. For more details, check the paper here!
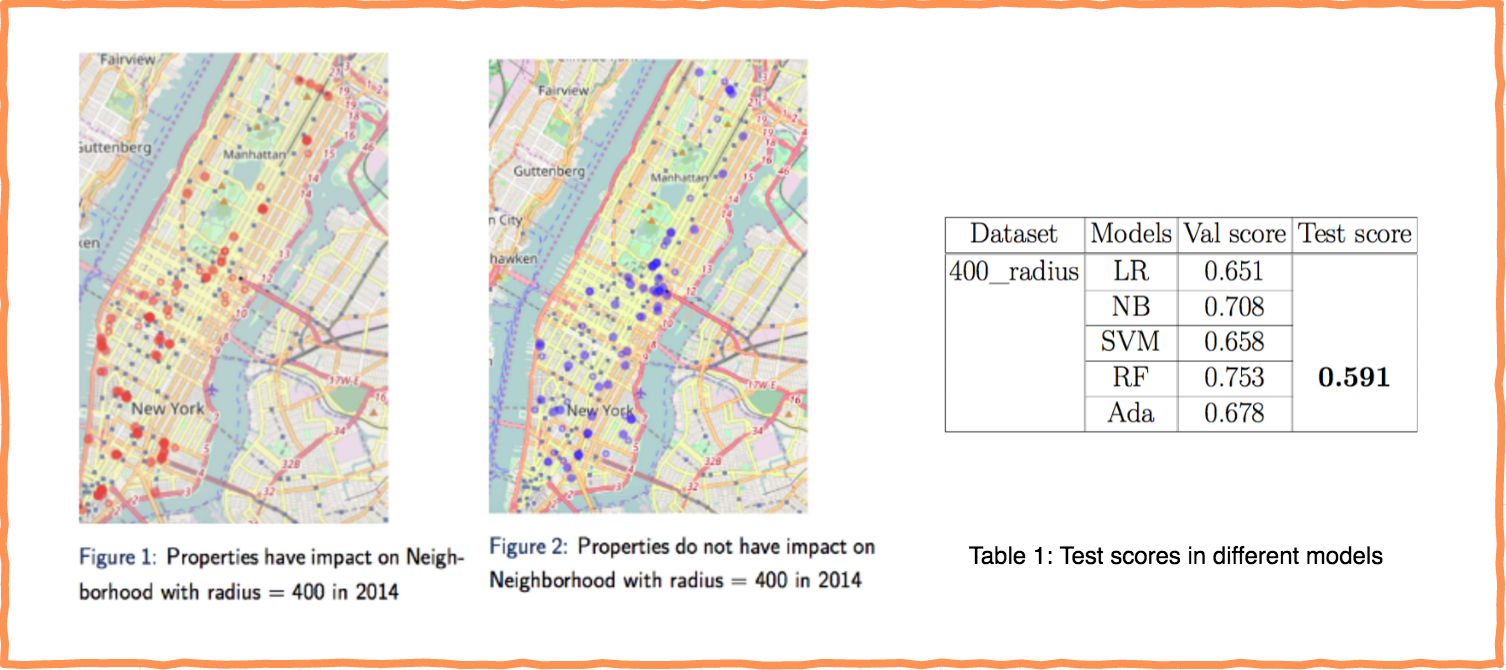
Predict and Quantify Development Influence
The real estate market is a key pillar industry in large cities. From everyday experience, high property value often indicates prosperity of certain areas. We intend to build a system which collects related data, analyses the factors which are of potential to influence the nearby real estate market, and throw out building suggestion to some newly building proposals.
We applied different machine learning models, such as logistic regression (LR), support vector machine (SVM), random forest (RF), naive bayes (NB) and AdaBoost(Ada) to find the main factors that boost properties' prices, and predict the future price trend. For more details about the project, check our poster here!
Apparel Classification
The objective of our project is to classify clothes types based on scanning and analyzing clothes pictures. We implemented a web scraper to extract approximately 3000 clothes pictures from Polyvore, and exploited the traditional image recognition techniques and
deep convolutional neural network model to do this task. The results posit a success of applying such techniques to this task, and we are looking forward to industry level deployment. For more details about the project, check our paper here!

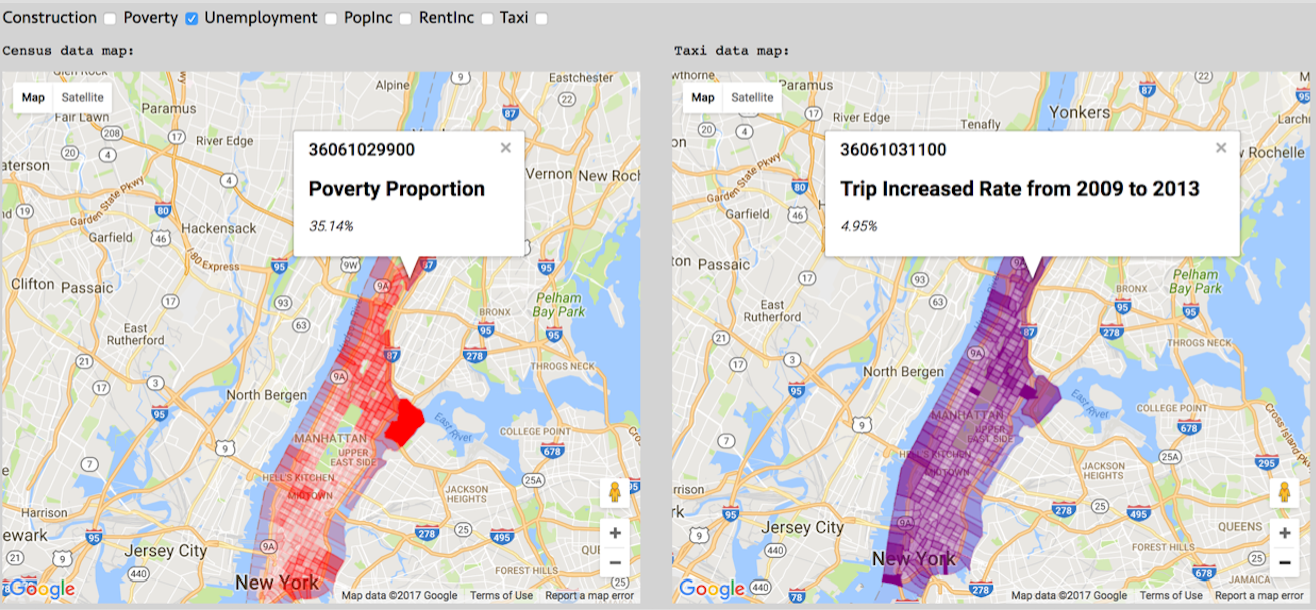
Gentrification Detection
Gentrification impacts almost every aspect of our lives nowadays in cities. From a data science perspective, we are developing techniques that quantify the gentrification effect with corresponding metrics. Breifly, we make leverage of two datasets that concerns taxi trips, and attempts to discover the causality and correlation
between gentrification and taxi trips. We conveyed a comprehensive analysis on the topic using proverty and unemployment ratio as the metric of Gentrification. Taxi influx implies the flow of middle/upper class people are moving into lower income area. For more details about the project, check our poster and github repository here!
Let's Chat
Reach out to me via
email: yg1281 at nyu dot edu
phone: 612-229-4097